Summary
Wikipedia annotation Edit Wikipedia article
The Rfam group coordinates the annotation of Rfam families in Wikipedia. This family is described by a Wikipedia entry Flavivirus 3' UTR. More...
This page is based on a Wikipedia article. The text is available under the Creative Commons Attribution/Share-Alike License.
Sequences
Alignment
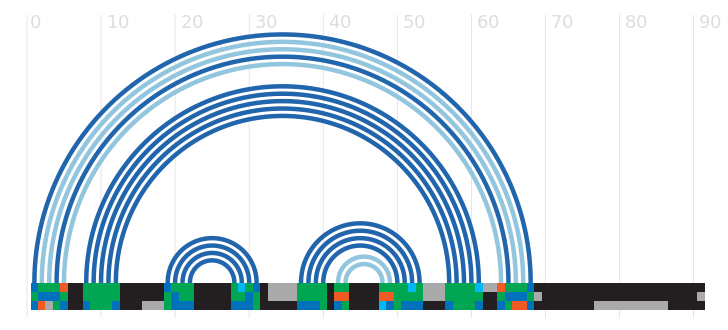
Seed alignment view
Download
Download a gzip-compressed, Stockholm-format file containing the seed alignment for this family. You may find RALEE useful when viewing sequence alignments.
Submit a new alignment
We're happy receive updated seed alignments for new or existing families. Submit your new alignment and we'll take a look.
Secondary structure
 Loading...
Loading...
Species distribution
Sunburst controls
HideWeight segments by...
Change the size of the sunburst
Colour assignments
 Archea
Archea
|
 Eukaryota
Eukaryota
|
 Bacteria
Bacteria
|
 Other sequences
Other sequences
|
 Viruses
Viruses
|
 Unclassified
Unclassified
|
 Viroids
Viroids
|
 Unclassified sequence
Unclassified sequence
|
Selections
Click on a node to select that node and its sub-tree.
Clear selection
This visualisation provides a simple graphical representation of the distribution of this family across species. You can find the original interactive tree in the adjacent tab. More...
Tree controls
HideThe tree shows the occurrence of this RNA across different species. More...
Loading...
Please note: for large trees this can take some time. While the tree is loading, you can safely switch away from this tab but if you browse away from the family page entirely, the tree will not be loaded.
Trees
This page displays the predicted phylogenetic tree for the alignment. More...
Note: You can also download the data file for the seed tree.
References
This section shows the database cross-references that we have for this Rfam family.
Literature references
-
Pijlman GP, Funk A, Kondratieva N, Leung J, Torres S, van der Aa L, Liu WJ, Palmenberg AC, Shi PY, Hall RA, Khromykh AA Cell Host Microbe. 2008;4:579-591. A highly structured, nuclease-resistant, noncoding RNA produced by flaviviruses is required for pathogenicity. PUBMED:19064258
-
Moon SL, Anderson JR, Kumagai Y, Wilusz CJ, Akira S, Khromykh AA, Wilusz J RNA. 2012;18:2029-2040. A noncoding RNA produced by arthropod-borne flaviviruses inhibits the cellular exoribonuclease XRN1 and alters host mRNA stability. PUBMED:23006624
-
Villordo SM, Filomatori CV, Sanchez-Vargas I, Blair CD, Gamarnik AV PLoS Pathog. 2015;11:e1004604. Dengue virus RNA structure specialization facilitates host adaptation. PUBMED:25635835
-
Ng WC, Soto-Acosta R, Bradrick SS, Garcia-Blanco MA, Ooi EE Viruses. 2017; [Epub ahead of print] The 5' and 3' Untranslated Regions of the Flaviviral Genome. PUBMED:28587300
-
Iwakawa HO, Mizumoto H, Nagano H, Imoto Y, Takigawa K, Sarawaneeyaruk S, Kaido M, Mise K, Okuno T J Virol. 2008;82:10162-10174. A viral noncoding RNA generated by cis-element-mediated protection against 5'->3' RNA decay represses both cap-independent and cap-dependent translation. PUBMED:18701589
-
Steckelberg AL, Akiyama BM, Costantino DA, Sit TL, Nix JC, Kieft JS Proc Natl Acad Sci U S A. 2018;115:6404-6409. A folded viral noncoding RNA blocks host cell exoribonucleases through a conformationally dynamic RNA structure. PUBMED:29866852
-
Steckelberg AL, Vicens Q, Costantino DA, Nix JC, Kieft JS RNA. 2020; [Epub ahead of print] The crystal structure of a Polerovirus exoribonuclease-resistant RNA shows how diverse sequences are integrated into a conserved fold. PUBMED:32848042
External database links
| Sequence Ontology: | SO:0000837 (UTR_region); |
Curation and family details
This section shows the detailed information about the Rfam family. We're happy to receive updated or improved alignments for new or existing families. Submit your new alignment and we'll take a look.
Curation
| Seed source | Lamkiewicz K | ||||||
| Structure source | Predicted; LocARNA 2.0.0RC8 | ||||||
| Type | Cis-reg; | ||||||
| Author |
Lamkiewicz K
|
||||||
| Alignment details |
|
Model information
| Build commands |
cmbuild -F CM SEED
cmcalibrate --mpi CM
|
| Search command |
cmsearch --cpu 4 --verbose --nohmmonly -T 30.00 -Z 2958934 CM SEQDB
|
| Gathering cutoff | 50.0 |
| Trusted cutoff | 82.8 |
| Noise cutoff | 38.4 |
| Covariance model | Download |

